|
Hi, I'm Pranav. I am a PhD student in CS at UC Berkeley, advised by Prof. Sergey Levine. In my research I investigate how to train robots with general purpose intelligence. I am graciously supported in part by the NSF Graduate Research Fellowship. Previously, I completed my BS in Computer Science at UT Austin, where I was a member of the Turing Scholars and Dean’s Scholars honors programs and was fortunate to be advised by Prof. Joydeep Biswas, Prof. Eunsol Choi, and Prof. Yuke Zhu. Email / Google Scholar / GitHub / Twitter |

|
||||||||||||||||||||||||
Recent News
|
|||||||||||||||||||||||||
|
|

|
Pranav Atreya*, Karl Pertsch*, Tony Lee*, ...RoboArena Team ArXiv Preprint, 2025 paper / website RoboArena is a distributed (7+ partner institutions) real-world generalist robot policy benchmark. It aims to provide comprehensive evaluation of user submitted robot policies in diverse real-world scenarios. It is built on the idea that we can scale real-world evaluations in both number and diversity if we let robot evaluators pick any scene and task for each evaluation, and run evals A/B style. Check out the website for more details! |

|
Zhiyuan Zhou, Pranav Atreya, You Liang Tan, Karl Pertsch, Sergey Levine ArXiv Preprint, 2025 paper / website Evaluating robot policies is a laborous, time-consuming process, and so far needs to be done by humans. It turns out if we train specialized reset policies and a success classifier, we can automate away all human involvement. Evaluations are still done in the real world, so they are trustworthy and accurate, but now they're also fully autonomous and scalable. |

|
Zhiyuan Zhou*, Pranav Atreya*, Abraham Lee, Homer Walke, Oier Mees, Sergey Levine CoRL, 2024 paper / website Robot learning requires data, but does the data need to be human collected? We find that we can boostrap a self-improvement process with a pre-trained policy and VLMs, collecting autonomous data at scale that can be used to improve the policy completely on its own. |
|
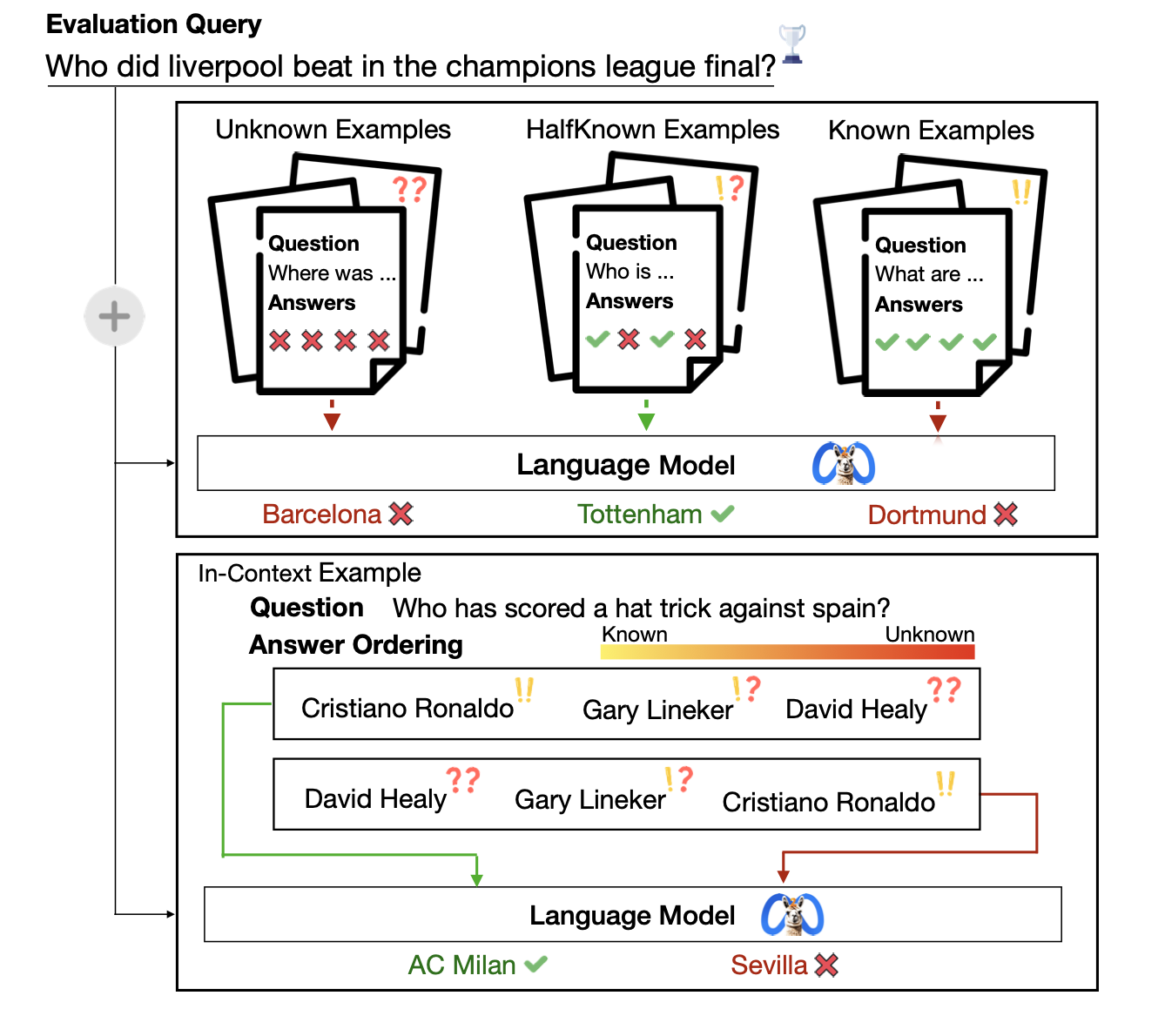
Yoonsang Lee*, Pranav Atreya*, Xi Ye, Eunsol Choi NAACL Findings, 2024 arXiv / website What prompts elicit language models to best answer knowledge intensive questions? We find that a mix of in-context examples that the model knows how to answer and doesn't know yields optimal QA performance. |

|
Kevin Black*, Mitsuhiko Nakamoto*, Pranav Atreya, Homer Walke, Chelsea Finn, Aviral Kumar, Sergey Levine ICLR, 2024 arXiv / website SuSIE leverages the internet pretraining of image generation models like InstructPix2Pix to achieve zero-shot robot manipulation on unseen objects, distractors, and scenes. |
|
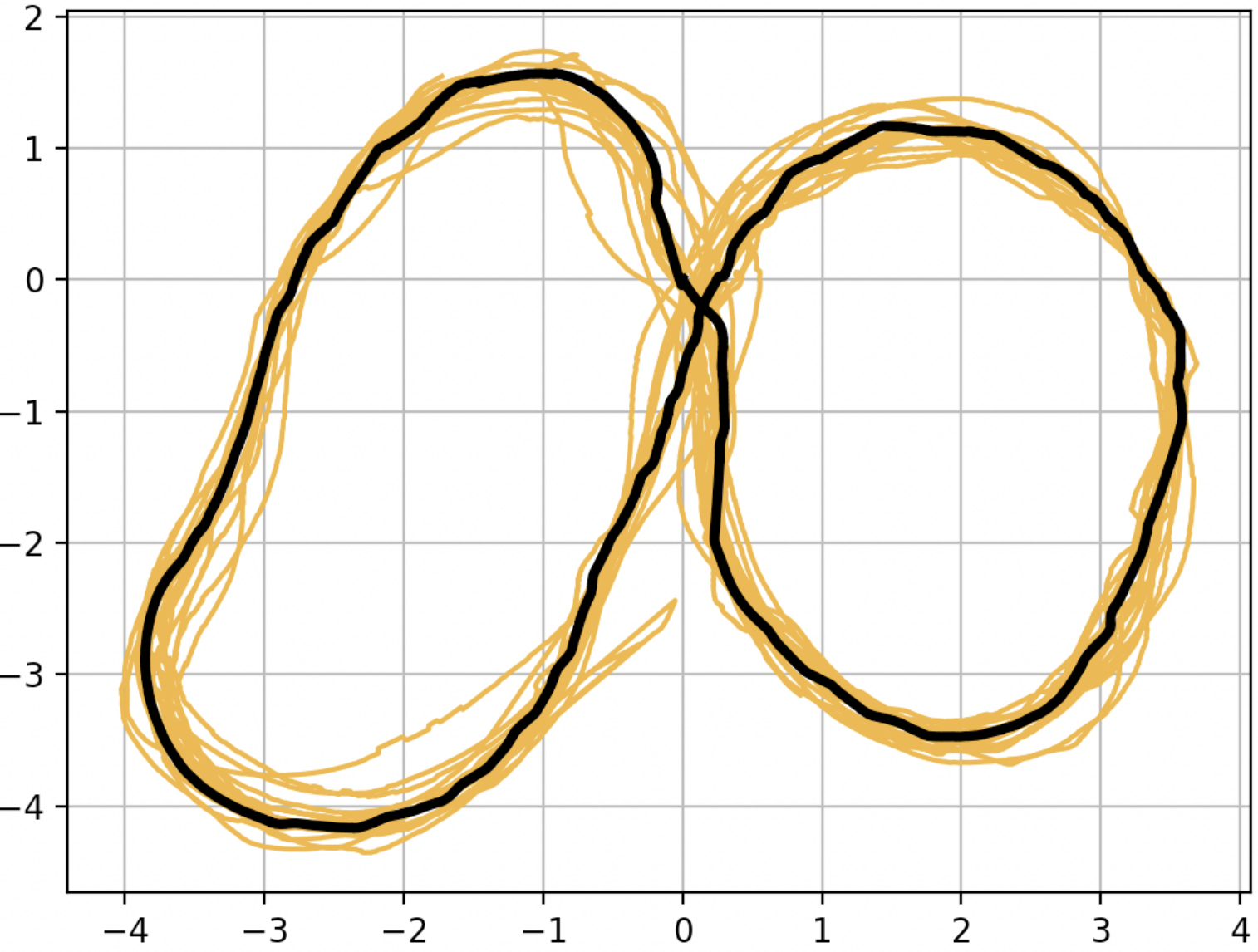
Pranav Atreya, Haresh Karnan, Kavan Singh Sikand, Xuesu Xiao, Sadegh Rabiee, Joydeep Biswas IROS, 2022 arXiv / video We devise Optim-FKD, a new paradigm for accurate, high speed control of a robot using a learned forward kinodynamic model and non-linear least squares optimization. |

|
Haresh Karnan, Kavan Singh Sikand, Pranav Atreya, Sadegh Rabiee, Xuesu Xiao, Garrett Warnell, Peter Stone, Joydeep Biswas IROS, 2022 arXiv / video In this work we learn a visual inverse kinodynamic model conditioned on image patches of the terrain ahead to better enable high-speed navigation on multiple different terrains. |

|
Pranav Atreya, Joydeep Biswas AAMAS, 2022 arXiv / video Optimal sampling-based motion planning algorithms when applied to kinodynamic planning make a trade off between computational efficiency and solution quality. With S3F we demonstrate that both are attainable by proposing a new way to learn the steering function required by these sampling-based planners. |







Website adapted from Jon Barron